One thing you can do to improve the accessibility of your work is to always ensure things have accessible names. Unique and useful names, ideally, so that they can be used for navigation. In this post I’ll explain how browsers decide on the names for links, form fields, tables and form groups.
This post is based on part of my talk 6 ways to make your site more accessible, that I gave at WordCamp Rotterdam last week.
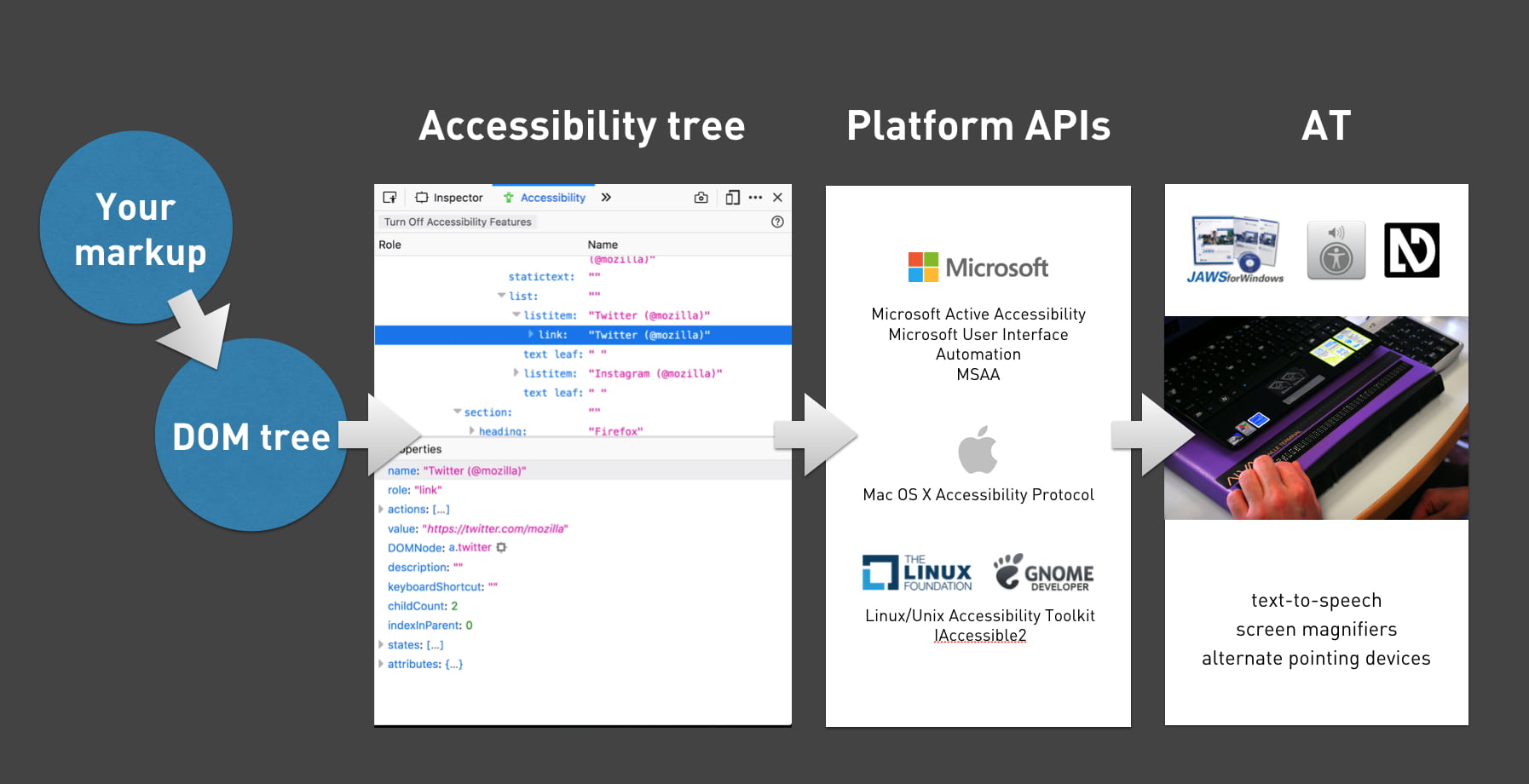
Accessibility Tree
When a user accesses your site, the server will send markup to the browser. This gets turned into trees. We’re probably all familiar with the DOM tree, a live representation of your markup, with all nodes turned into objects that we can read properties of and perform all sorts of functions on.
What many people don’t know, is that there is a second structure that the browser can generate: the accessibility tree. It is based off the DOM tree, and contains all meta information relation related to accessibility: roles, names and properties. Another way to say it: the accessibility tree is how your page gets exposed to assistive technologies.
Assistive Technology
Assistive Technology (AT) is an umbrella term for all sorts of tools that people use to improve how they access things. For computers and the web, they include:
- alternate pointing devices, like a mouse that attaches to a user’s head
- screen magnifiers, they enlarge the screen
- braille bars, they turn what’s on the screen into braille
- screenreaders, they read out what’s on the screen to the user

All of these tools, to work efficiently, need to know what’s happening on the screen. To find out, they access Platform APIs, built into every major platform, including Windows, Mac and Linux. The APIs can expose everything in the OS, so they know about things like the Start Bar, Dock or the browser’s back button. One thing they don’t know about, is the websites you access. They can’t possibly have the semantic structure of every website built into their APIs, so they rely on an intermediary — this is where the Accessibility Tree comes in. It exposes your website’s structure. As I said, it is based on the DOM, which is based on our mark-up.
 A handy flow chart
A handy flow chart
The accessibility tree exposes roles (is this a header, a footer, a button, a navigation?), names (I’ll get into those in a bit), properties (is the hamburger menu open or closed, is the checkbox checked or not, et cetera) and a number of other things.
If you want to see what this looks like on a site of your choosing, have a look at the Accessibility Panel in Firefox Developer Tools, or check out the accessibility info boxes in Chrome, Safari Tech Preview or Edge developer tools.
Accesssible name computation
Names are one of the things the accessibility tree exposes for its objects. What a thing’s name is, gets derived from markup. There are many aspects that can influence this. If you want to know this in detail, check out the Accessible Name and Description Computation Specification.
Unique names help distinguish
Before going more into how to expose names, let’s look at which names we want. What the names are is crucial for whether they are accessible or not.
What if your family has four cats, and each of them is named ”Alice”? This would be incredibly impractical, as it would make communication difficult. “Has Alice been fed yet?”, you might wonder. “Is Alice outside?”, you might ask your partner. Ambiguity is impractical. Yet, this is what we do when our homepage has four news items, with each “Read more” as its link text.
 Imagine all of your cats were named Alice (photo: stratman2 on Flickr)
Imagine all of your cats were named Alice (photo: stratman2 on Flickr)
This is very common, sadly. In the WebAIM Million project, in which WebAIM looked at over a million sites and ran automated accessibility checks, they found:
24.4% of pages had links with ambiguous link text, such as ‘click here’, ‘more’, ‘continue’, etc.
Reusing “Read more” as the link text for each news item makes our code and content management simpler, but it provides bad usability for screenreader users. When they use the link shortcut to browse through links on the page, they will have no idea where each links leads them. In the example above, when you ask an AT to read out all links, it will read “Link Read more, Link Read more, Link Read more, Link Read more”.
Naming things
So, unique and descriptive names are useful to AT users. Let’s look at which HTML can help us provide names. As I said before, the heuristics for determining names are in a spec, but with just HTML providing names for most things is trivial. The following section is mostly useful for people whose HTML is rusty.
Links
The contents of an <a> element will usually become the accessible name.
So in:
<a href="/win-a-prize">
Win a prize</a>the accessible name would compute as “Win a prize”.
If there’s just an image, its alt text can also get used:
<a href="/win-a-prize">
<img src="prize.png" alt="Win a prize" />
</a>And, to be clear, if there’s nothing provided, the name would be null or empty string, so some people would be unable to win any prize.
Form fields
Form fields get labelled using the <label> element. In their aforementioned research, WebAIM also found:
59% of form inputs were not properly labeled.
Let’s look at what a labelling mistake could look like:
<div>Email</div> <!-- don't do this-->
<input type="email" id="email" />In this example, the word “Email” appears right before the input, so a portion of your users might be able to visually associate that they belong together. But they aren’t associated, so the input has no name— it will compute as null or '' in the accessibility tree.
Associating can be done by wrapping the input in a <label> element, or by using a for attribute that matches the input’s id attribute:
<label for="email">Email</label> <!-- do this-->
<input type="email" id="email" />Tables
To give a table a name, you can use its <caption> element. This is used as the first element in a <table>.
Groups in a form
Within forms, you sometimes want to group a set of form inputs, for example a collection of radiobuttons or checkboxes that answer the same question. HTML has <fieldset> for grouping form elements. To name this group as a whole, use the <legend> element:
<fieldset>
<legend>Don't you love HTML?</legend>
<input type="radio" name="yesno" id="yes"/>
<label for="yes">Yes</label>
<input type="radio" name="yesno" id="no"/>
<label for="no">No</label>If you were to inspect this fieldset in the accessibility tree, you will notice that the group is now known as “Don’t you love HTML?”.
What about ARIA?
Those familiar with the Accessible Name and Description Computation spec might wonder at this point: doesn’t ARIA also let us give elements accessible names? It totally does, for instance through the aria-label / aria-labelledby attributes. When added to an element, they overwrite the accessible name (if there was one).
Good reasons to prefer standard HTML tags over ARIA include:
- better browser support (a lot of browsers support most ARIA, but all support all HTML, generally speaking)
- more likely to be understood by current or future team members that don’t have all the ARIA skills
- less likely to be forgotten about when doing things like internationalisation (in your own code, or by external tools like Google Translate, see Heydon Pickering’s post aria-label is a xenophobe)
Sometimes ARIA can come in handy, for example if an element doesn’t play along well with your CSS (like if you want a Grid Layout in a fieldset), or if your (client’s) CMS is very inflexible.
It’s the markup that matters
In modern browsers, our markup becomes an accessibility tree that ultimately informs what our interface looks like to assistive technologies. It doesn’t matter as much whether you’ve written this markup:
- in a
.htmlfile - in Twig, Handlebars or Nunjucks
- as the
<template>in a Vue Single File Component - exported in the JSX of your React component
- outputted by a weird legacy CMS
It is which markup that determines if your site is pleasurable to experience for AT users. In short: it’s the markup that matters
There’s good chance your site already uses all of the above HTML elements that name things. They have existed for many years. But I hope this post explains why it is worth the effort to always ensure the code your site serves to users, includes useful names for assistive technologies. Markup-wise it is trivial to assign names to all things on our site, the real challenge is probably two fold. It’s about content (do we come up with useful and distinguishable names), and about tech (can we ensure the right markup gets into our user’s DOMs).
Comments, likes & shares (75)
patak, Matt Edgar, Justin 👋🏻, Juhis, Kees de Kooter :mastodon:, Harley Eades, Sami Määttä, Accessabilly, James Bateson, Sheri Richardson, Anuradha Kumari, Logan, Lenn Grey :v_enby: :v_trans:, Gustavo :mastodon_com_br:, Max R. Cerrina (he/him), Sammie, JP de Vries, André 📔 uselinked.com, Stephen B, Meagan, Lexi, グレェ「grey」, JeffGPT, Tatiana Fokina, Joe Lanman, The Samus Aran-Contra affair, Chris, Chris :python: :rust:, Luz De León, max k, Benjy Stanton 🦣 @benjystanton@mastodon.social, Leire Díez, Amy, Martin Lexelius, Casey Robinson👨🏻💻, 🦞 Todd and Creyawn liked this
Tim Kraut, Линкольн | :bantu: | لينكولن, loapher, Juhis, Harley Eades, jpagroenen, Accessabilly, Sarah Fossheim :they_them:, Drazi Crendraven :verified:, Max R. Cerrina (he/him), Misty, Web Axe, Mario Trost, Marjon Bakker, Florian Geierstanger, Jeremy Neander, Luz De León, Amy and enqueue reposted this
HTML, CSS, JavaScript, Python, PHP, C++, Dart — there are so many programming languages out there and you may even be totally fluent in several of them! But as we aim to write more and better code, the way we write and communicate in everyday language becomes more and more important… and perhaps even overlooked.
The way we write about and around code is arguably as important as the code itself. And despite where you fall on that line, we can all agree that our words have the potential to both help and hurt code’s effectiveness.
In this article, I want to outline how these two seemingly distinct fields — programming and writing — can come together and take our developer skills to the next level.
Wait, technical writing? Yes, that’s exactly what I mean. I truly believe we are all writers in one sense or another. And I’m here to give you a primer with writing tips, advice, and examples for how it can make you both a better developer and communicator.
Table of contents
Table of contents
Technical writing is everywhere
What is good grammar?
Writing code comments
Writing pull requests
Reporting bugs
Communicating with clients
Writing microcopy
Writing accessible markup
Conclusion
Technical writing resources
Technical writing is everywhere
Last year, the team behind the popular Mac Git client, Tower, polled more than 4,000 developers and found that nearly 50% of them spent between 3-6 hours a day writing code.
And yes, that’s one survey polling a pretty niche group, but I imagine many of us fall somewhere in that range. Whatever the case, a developer isn’t writing code 24/7, because as this poll suggests, we’re spending plenty of time doing other things.
That might include:
demoing a new feature,documenting that new feature,updating a work ticket related to that new feature, orbacklogging work to support that new feature.
Of course, there’s always time for bathroom breaks and Wordle too.
Anyway, most of the things we typically do involve communicating with people like your team, colleagues, clients, users, and other developers.
So we do spend a good chunk of our time communicating with humans through words in addition to the communication we have with computers through code. Words are written language. And if we wrote our words better, we’d communicate better. When we communicate better, we’re more likely to get what we want.
That’s Technical Writing 101.
And it doesn’t even end here.. Some programmers also like to make their own products, which means they need to make marketing part of their job. Technical writing plays a huge role in that too. So, yeah. I think it’s pretty fair to say that technical writing is indeed everywhere.
What is good grammar?
With so many programming languages out there, the last thing we want is to learn another one.
Grammar is an integral part of English, and it unlocks the full potential of communication. It makes us more formal, professional, and coherent.
Let me give you a quick rundown on language.
The English syntax
Just like programming languages, English has a well-defined syntax, and it starts with words.
Words are the building blocks of English, and they fall into eight buckets:
Nouns
These can be names of people, animals, places, concepts, and objects.
Example:
CSS is one of the core languages of front-end development.
Verbs
Verbs convey action. Even “is” can be considered an action.
Example:
Marcia codes in the morning and answers emails in the afternoon.
Adjectives
Adjectives are how we describe nouns. They’re like meta that adds more detail to a sentence to paint a vivid picture.
Examples:
CSS is an elegant and poetic language.The HTML for tables is complex and cumbersome.The Box Model is important to understand CSS.
Prepositions
Prepositions create a relationship between a noun and other words, often indicating direction, time, location, and space.
Examples:
Did you commit your work to the repo?What is the best approach for this component?We conducted interviews with real users.
Adverbs
Sometimes actions need to be more specific, so we use adverbs such as “runs fast” and “compiles slowly.” They often end in “-ly.”
Examples:
This is easily the best idea of them all.Chip waited patiently for Dale’s feedback.The team worked diligently on the project.
Conjunctions
Conjunctions connect phrases in a sentence. Remember this classic song from the show School House Rocks?
Examples:
CSS for styling while HTML is for markup.Yes, I write code, but I also work on design.That fixes the bug. Yet it introduced a new one.
Transitions
Paragraphs are made of sentences that are connected to each other using transitions.
Examples:
There are many programming languages. However, only a few are used in the web industry.First, clone the directory.I like this approach but on the other hand, I know another one.
Pronouns
When nouns become repetitive, we replace them with pronouns such as: “he,” “it,” and “that.”
Examples:
CSS is a stylesheet language. We use it to style websites.Tony loves to code and he practices every day.Our customers are tech-savvy because they know code.
Think of these like UI components: they are modular pieces you can move around to construct a complete and robust sentence, the same way you might piece together a complete and robust UI. Do all of the components need to be there all of the time? Certainly not! Assemble a sentence with the pieces you need to complete the experience, just as you would with an interface.
Voice and tone
Vocabulary, punctuation, sentence structure, and word choice. These are all the ingredients of English. We use them to share ideas, communicate with our friends and family, and send emails to our coworkers.
But it’s crucial to consider the sound of our messages. It’s amazing how one exclamation point can completely shift the tone of a message:
I like programming.I like programming! 🙂
It’s easy to confuse voice for tone, and vice versa.
Voice is what concerns our choice of words, which depends on context. For example, a tutorial for beginners is more likely to use slang and informal language to convey a friendly voice, whereas documentation might be written in a formal, serious, and professional manner in an effort to get straight to the point.
The same message, written in two different voices:
Fun: “Expand your social network and stay updated on what’s trending now.”Serious: “Find jobs on one of the largest social networking apps and online jobs market.”
It’s not unusual to accidentally write messages that come across as condescending, offensive, and unprofessional. This is where tone comes into play. Read your messages out loud, get other people to read them for you, and experiment with your punctuation and sentence structure. That’s how you hone your tone.
Here’s another way to think of it: your voice never changes, but your tone does. Your voice is akin to who you are as a person, whereas tone is how you respond in a given situation.
Active and passive voice
A sentence always contains an actor, a verb, and a target. The order in which these come determines if the sentence is written in an active or passive voice.
The actor comes first in an active voice. For example: “CSS paints the background.”
Sentences that use an active voice are more straightforward than their counterparts. They’re clearer, shorter, and more understandable — perfect for a more professional voice that gets straight to the point.
With a passive voice, the actor comes last. (See what I did there?) That means our actor — CSS in this case — comes at the end like this: “The background is painted by CSS.”
Readers usually convert a passive voice to an active voice in their heads, resulting in more processing time. If you’ve ever heard that writing in an active voice is better, this is usually the reason why. Tech writers prefer the active voice most of the time, with very few exceptions such as citing research: “It has been suggested that …”
But that doesn’t mean you should always strive for an active voice. Switching from one to the other — even in the same paragraph — can make your content flow more seamlessly from one sentence to another if used effectively.
Avoiding mistakes
Grammar is all about the structure and correctness of language, and there’s nothing better to achieve that than a quick proofreading of your document. It’s very important to rid your writings of spelling mistakes, grammar issues, and semantic imperfections.
At the end of this article, I’ll show you the invaluable tools that professionals use to avoid writing mistakes. Obviously, there are built-in spell checkers in just about everything these days; our code editors even have spell-checking and linting plugins to help prevent mistakes.
But if you’re looking for a one-stop tool for all-things grammar, Grammarly is one of the most widely-used tools. I’m not getting a kickback for that or anything. It’s just a really great tool that many editors and writers use to write clean and clear content — similar to how you might use Emmet, eslint, or any other linter to write clean and clear code.
Writing code comments
The things we write for other developers can have a big impact on the overall quality of our work, whether it’s what we write in the code, how we explain the code, or how we give feedback on a piece of code.
It’s interesting that every programming language comes with a standard set of features to write a comment. They should explain what the code is doing. By that, I don’t mean vague comments like this:
red *= 1.2 // Multiply `red` by 1.2 and re-assign it
Instead, use comments that provide more information:
red *= 1.2 // Apply a ‘reddish’ effect to the image
It’s all about context. “What kind of program am I building?” is exactly the kind of question you should be asking yourself.
Comments should add value
Before we look at what makes a “good” code comment, here are two examples of lazy comments:
const age = 32 // Initialize `age` to 32
filter: blur(32px); /* Create a blur effect with a 32px radius */
Remember that the purpose of a comment is to add value to a piece of code, not to repeat it. If you can’t do that, you’re better off just leaving the code as-is. What makes these examples “lazy” is that they merely restate what the code is obviously doing. In this case, the comments are redundant because they tell us what we already know — they aren’t adding value!
Comments should reflect the current code
Out-of-date comments are no rare sight in large projects; dare I say in most projects.
Let’s imagine David, a programmer and an all-around cool guy to hang out with. David wants to sort a list of strings alphabetically from A to Z, so he does the obvious in JavaScript:
cities = sortWords(cities) // sort cities from A to Z
David then realizes that sortWords() actually sorts lists from Z to A. That’s not a problem, as he can simply reverse the output:
cities = sortWords(cities) // sort cities from A to Z
cities = reverse(cities)
Unfortunately, David didn’t update his code comment.
Now imagine that I didn’t tell you this story, and all you saw was the code above. You’d naturally think that after running that second line of code, `cities` would be sorted from Z to A! This whole confusion fiasco was caused by a stale comment.
While this might be an exaggerated example, something similar can (and often does) happen if you’re racing against a close deadline. Thankfully, this can be prevented by following one simple rule… change your comments the same time you change the code.
That’s one simple rule that will save you and your team from a lot of technical debt.
Now that we know what poorly written comments look like, let’s look at some good examples.
Comments should explain unidiomatic code
Sometimes, the natural way of doing things isn’t right. Programmers might have to “break” the standards a bit, but when they do, it’s advisable to leave a little comment explaining their rationale:
function addSetEntry(set, value) {
/* Don’t return `set.add` because it’s not chainable in IE 11. */
set.add(value);
return set;
}
That’s helpful, right? If you were responsible for reviewing this code, you may have been tempted to correct it without that comment there explaining what’s up.
Comments can identify future tasks
Another useful thing to do with comments is to admit that there’s more work to be done.
// TODO: use a more efficient algorithm
linearSort(ids)
This way, you can stay focused on your flow. And at a later date, you (or someone else) can come back and fix it.
Comments can link back to the source
So, you just found a solution to your problem on StackOverflow. After copy-pasting that code, it’s sometimes a good thing to keep a link to the answer that helped you out so you can come back to it for future reference.
// Adds handling for legacy browsers
// https://stackoverflow.com/a/XXXXXXX
This is important because solutions can change. It’s always good to know where your code came from in case it ever breaks.
Writing pull requests
Pull requests (PRs) are a fundamental aspect of any project. They sit at the heart of code reviews. And code reviews can quickly become a bottleneck in your team’s performance without good wording.
A good PR description summarizes what change is being made and why it’s being made. Large projects have a pull request template, like this one adapted from a real example:
## Proposed changes
Describe the big picture of your changes here to communicate to the maintainers why we should accept this pull request.
## Types of changes
What types of changes does your code introduce to Appium?
– [ ] Bugfix (non-breaking change which fixes an issue)
– [ ] New feature (non-breaking change which adds functionality)
– …
## Checklist
– [ ] I have read the CONTRIBUTING doc
– [ ] I have signed the CLA
– [ ] Lint and unit tests pass locally with my changes
## Further comments
If this is a relatively large or complex change, kick off the discussion by explaining why you chose the solution you did and what alternatives you considered, etc…
Avoid vague PR titles
Please avoid titles that look like this:
Fix build.Fix bug.Add patch.
These don’t even attempt to describe what build, bug, or patch it is we’re dealing with. A little extra detail on what part of the build was fixed, which bug was squashed, or what patch was added can go a long way to establishing better communication and collaboration with your colleagues. It level-sets and gets folks on the same page.
PR titles are traditionally written in imperative tense. They’re a one-line summary of the entire PR, and they should describe what is being done by the PR.
Here are some good examples:
Support custom srcset attributes in NgOptimizedImageDefault image config to 75% image qualityAdd explicit selectors for all built-in ControlValueAccessors
Avoid long PRs
A large PR means a huge description, and no one wants to review hundreds or thousands of lines of code, sometimes just to end-up dismissing the whole thing!
Instead, you could:
communicate with your team through Issues,make a plan,break down the problem into smaller pieces, orwork on each piece separately with its own PR.
Isn’t it much cleaner now?
Provide details in the PR body
Unlike the PR title, the body is the place for all the details, including:
Why is the PR being done?Why is this the best approach?Any shortcomings to the approach, and ideas to solve them if possibleThe bug or ticket number, benchmark results, etc.
Reporting bugs
Bug reports are one of the most important aspects of any project. And all great projects are built on user feedback. Usually, even after countless tests, it’s the users that find most bugs. Users are also great idealists, and sometimes they have feature ideas; please listen to them!
For technical projects, all of this stuff is done by reporting issues. A well-written issue is easy for another developer to find and respond to.
For example, most big projects come with a template:
<!– Modified from angular-translate/angular-translate –>
### Subject of the issue
Describe your issue here.
### Your environment
* version of angular-translate
* version of angular
* which browser and its version
### Steps to reproduce
Tell us how to reproduce this issue.
### Expected behavior
Tell us what should happen.
### Actual behavior
Tell us what happens instead.
Gather screenshots
Capture the issue using your system’s screen-shooting utility.
If it’s a screenshot of a CLI program, make sure that the text is clear. If it’s a UI program, make sure the screenshot captures the right elements and states.
You may need to capture an actual interaction to demonstrate the issue. If that’s the case, try to record GIFs using a screen-recording tool.
How to reproduce the problem
It’s much easier for programmers to solve a bug when it’s live on their computer. That’s why a good commit should come with the steps to precisely reproduce the problem.
Here’s an example:
Update: you can actually reproduce this error with objects:
“`html
<div *ngFor=”let value of objs; let i = index”>
<input [ngModel]=”objs[i].v” (ngModelChange)=”setObj(i, $event)” />
</div>
“`
“`js
export class OneComponent {
obj = {v: ‘0’};
objs = [this.obj, this.obj, this.obj, this.obj];
setObj(i: number, value: string) {
this.objs[i] = {v: value};
}
}
“`
The bug is reproducible as long as the trackBy function returns the same value for any two entries in the array. So weird behavior can occur with any duplicate values.
Suggest a cause
You’re the one who caught the bug, so maybe you can suggest some potential causes for why it’s there. Maybe the bug only happens after you encounter a certain event, or maybe it only happens on mobile.
It also can’t hurt to explore the codebase, and maybe identify what’s causing the problem. Then, your Issue will be closed much quicker and you’re likely to be assigned to the related PR.
Communicating with clients
You may work as a solo freelancer, or perhaps you’re the lead developer on a small team. In either case, let’s say you’re responsible for interfacing with clients on a project.
Now, the programmer stereotype is that we’re poor communicators. We’ve been known to use overly technical jargon, tell others what is and is not possible, and even get defensive when someone questions our approach.
So, how do we mitigate that stereotype? Ask clients what they want, and always listen to their feedback. Here’s how to do that.
Ask the right questions
Start by making sure that you and the client are on the same page:
Who is your target audience?What is the goal of the site?Who is your closest competitor and what are they doing right?
Asking questions is also a good way to write positively, particularly in situations when you disagree with a client’s feedback or decision. Asking questions forces that person to support their own claims rather than you attacking them by defending your own position:
Are you OK with that even if it comes with an additional performance cost?Does moving the component help us better accomplish our objective?Great, who is responsible to maintain that after launch? Do you know offhand if the contrast between those two colors passes WCAG AA standards?
Questions are a lot more innocent and promote curiosity over animosity.
Sell yourself
If you’re making a pitch to a prospective client, you’re going to need to convince them to hire you. Why should the client choose you? It’s important to specify the following:
Who you areWhat you doWhy you’re a good fit for the jobLinks to relevant work you’ve done
And once you get the job and need to write up a contract, remember that there’s no content more intimidating than a bunch of legalese. Even though it’s written for design projects, the Contract Killer can be a nice starting point for writing something much friendlier.
Your attention to detail could be the difference between you and another developer trying to win the same project. In my experience, clients will just as easily hire a develop they think they will enjoy working with than the one who is technically the most competent or experienced for the job.
Writing microcopy
Microcopy is the art of writing user-friendly UI messages, such as errors. I’ll bet there have been times where you as a developer had to write error messages because they were put on the backburner all the way to launch time.
That may be why we sometimes see errors like this:
Error: Unexpected input (Code 693)
Errors are the last thing that you want your users to deal with. But they do happen, and there’s nothing we can do about it. Here are some tips to improve your microcopy skills.
Avoid technical jargon
Most people don’t know what a server is, while 100% of programmers do. That’s why it’s not unusual to see uncommon terms written in an error message, like API or “timeout execution.”
Unless you’re dealing with a technical client or user base, It’s likely that most of your users didn’t take a computer science course, and don’t know how the Internet works, and why a particular thing doesn’’t work. Hence, the error.
Therefore, a good error message shouldn’t explain why something went wrong, because such explanations might require using scary technical terms. That’s why it’s very important to avoid using technical jargon.
Never blame the user
Imagine this: I’m trying to log into your platform. So I open my browser, visit your website, and enter my details. Then I’m told: “Your email/password is incorrect.”
Even though it seems dramatic to think that this message is hostile, it subconsciously makes me feel stupid. Microcopy says that it’s never okay to blame the user. Try changing your message to something less finger-pointy, like this this example adapted from Mailchimp’s login: “Sorry, that email-password combination isn’t right. We can help you recover your account.”
I’d also like to add the importance of avoiding ALL CAPS and exclamation points! Sure, they can be used to convey excitement, but in microcopy they create a sense of hostility towards the user.
Don’t overwhelm the user
Using humor in your microcopy is a good idea! It can lighten up the mood, and it’s an easy way to curb the negativity caused by even the worst errors.
But if you don’t use it perfectly, it can come across as condescending and insulting to the user. That’s just a big risk to take.
Mailchimp says it well:
[D]on’t go out of your way to make a joke — forced humor can be worse than none at all. If you’re unsure, keep a straight face.
(Emphasis mine)
Writing accessible markup
We could easily spend an entire article about accessibility and how it relates to technical writing. Heck, accessibility is often included in content style guides, including those for Microsoft and Mailchimp.
You’re a developer and probably already know so much about accessibility. You may even be one of the more diligent developers that makes accessibility a core part of your workflow. Still, it’s incredible how often accessibility considerations are put on the back burner, no matter how important we all know it is to make accessible online experiences that are inclusive of all abilities.
So, if you find yourself implementing someone else’s copywriting into your code, writing documentation for other developers, or even writing UI copy yourself, be mindful of some fundamental accessibility best practices, as they round out all the other advice for technical writing.
Things like:
Using semantic tags where possible (e.g. <nav>, <header>, <article>, etc.)Following a logical heading structureAdding alt text to imagesWatching for inline semantics (Mandy Michael has an exceptional article on this)
Andy Bell offers some relatively small things you can do to make content more accessible, and it’s worth your time checking them out. And, just for kicks, John Rhea shows off some neat editing tricks that are possible when we’re working with semantic HTML elements.
Conclusion
Those were six ways that demonstrate how technical writing and development coincide. While the examples and advice may not be rocket science, I hope that you found them useful, whether it’s collaborating with other developers, maintaining your own work, having to write your own copy in a pinch, or even drafting a project proposal, among other things.
The bottom line: sharpening your writing skills and putting a little extra effort into your writing can actually make you a better developer.
Technical writing resources
If you’re interested in technical writing:
Advice for Technical Writing (Chris Coyier)Google’s Technical Writing GuideTechnical Writing Fundamentals (GitLab)UX Writing: Study Guide (Nielson Norman Group)Write the Docs (Technical writing community)
If you’re interested in copywriting:
Copywriting 101 (Copyblogger)What is Copywriting? (Ionos)SEO Copywriting Guide (Semrush)Copywriting is Still Writing (The Guardian)
If you’re interested in microcopy:
Introduction to Microcopy (UX Planet)Apple’s Human Interface GuidelinesMicrosoft’s Writing Style GuideMailchimp Content Style Guide
If you’re interested in using a professional style guide to improve your writing:
MLA Writing Style GuideAP Writing Style GuideAPA Writing Style GuideChicago Writing Style Guide
If you’re interested in writing for accessibility:
Improve the readability of the content on your website (Andy Bell)15 Practices to Improve Your Website Accessibility (Bruce Lawson)Accessibility Testing Tools (Chris Coyier)Why Don’t Developers Tke Accessibility Seriously? (Melanie Sumner)Naming things to improve accessibility (Hidde de Vries)
Technical Writing for Developers originally published on CSS-Tricks. You should get the newsletter.
Related
HTML, CSS, JavaScript, Python, PHP, C++, Dart — there are so many programming languages out there and you may even be totally fluent in several of them! But as we aim to write more and better code, the way we write and communicate in everyday language becomes more and more important… and perhaps even overlooked.
The way we write about and around code is arguably as important as the code itself. And despite where you fall on that line, we can all agree that our words have the potential to both help and hurt code’s effectiveness.
In this article, I want to outline how these two seemingly distinct fields — programming and writing — can come together and take our developer skills to the next level.
Wait, technical writing? Yes, that’s exactly what I mean. I truly believe we are all writers in one sense or another. And I’m here to give you a primer with writing tips, advice, and examples for how it can make you both a better developer and communicator.
Table of contents
Technical writing is everywhere
Last year, the team behind the popular Mac Git client, Tower, polled more than 4,000 developers and found that nearly 50% of them spent between 3-6 hours a day writing code.
And yes, that’s one survey polling a pretty niche group, but I imagine many of us fall somewhere in that range. Whatever the case, a developer isn’t writing code 24/7, because as this poll suggests, we’re spending plenty of time doing other things.
That might include:
Of course, there’s always time for bathroom breaks and Wordle too.
Anyway, most of the things we typically do involve communicating with people like your team, colleagues, clients, users, and other developers.
So we do spend a good chunk of our time communicating with humans through words in addition to the communication we have with computers through code. Words are written language. And if we wrote our words better, we’d communicate better. When we communicate better, we’re more likely to get what we want.
That’s Technical Writing 101.
And it doesn’t even end here.. Some programmers also like to make their own products, which means they need to make marketing part of their job. Technical writing plays a huge role in that too. So, yeah. I think it’s pretty fair to say that technical writing is indeed everywhere.
What is good grammar?
With so many programming languages out there, the last thing we want is to learn another one.
Grammar is an integral part of English, and it unlocks the full potential of communication. It makes us more formal, professional, and coherent.
Let me give you a quick rundown on language.
The English syntax
Just like programming languages, English has a well-defined syntax, and it starts with words.
Words are the building blocks of English, and they fall into eight buckets:
Nouns
These can be names of people, animals, places, concepts, and objects.
Example:
CSS is one of the core languages of front-end development.
Verbs
Verbs convey action. Even “is” can be considered an action.
Example:
Marcia codes in the morning and answers emails in the afternoon.
Adjectives
Adjectives are how we describe nouns. They’re like meta that adds more detail to a sentence to paint a vivid picture.
Examples:
Prepositions
Prepositions create a relationship between a noun and other words, often indicating direction, time, location, and space.
Examples:
Adverbs
Sometimes actions need to be more specific, so we use adverbs such as “runs fast” and “compiles slowly.” They often end in “-ly.”
Examples:
Conjunctions
Conjunctions connect phrases in a sentence. Remember this classic song from the show School House Rocks?
Examples:
Transitions
Paragraphs are made of sentences that are connected to each other using transitions.
Examples:
Pronouns
When nouns become repetitive, we replace them with pronouns such as: “he,” “it,” and “that.”
Examples:
Think of these like UI components: they are modular pieces you can move around to construct a complete and robust sentence, the same way you might piece together a complete and robust UI. Do all of the components need to be there all of the time? Certainly not! Assemble a sentence with the pieces you need to complete the experience, just as you would with an interface.
Voice and tone
Vocabulary, punctuation, sentence structure, and word choice. These are all the ingredients of English. We use them to share ideas, communicate with our friends and family, and send emails to our coworkers.
But it’s crucial to consider the sound of our messages. It’s amazing how one exclamation point can completely shift the tone of a message:
It’s easy to confuse voice for tone, and vice versa.
Voice is what concerns our choice of words, which depends on context. For example, a tutorial for beginners is more likely to use slang and informal language to convey a friendly voice, whereas documentation might be written in a formal, serious, and professional manner in an effort to get straight to the point.
The same message, written in two different voices:
It’s not unusual to accidentally write messages that come across as condescending, offensive, and unprofessional. This is where tone comes into play. Read your messages out loud, get other people to read them for you, and experiment with your punctuation and sentence structure. That’s how you hone your tone.
Here’s another way to think of it: your voice never changes, but your tone does. Your voice is akin to who you are as a person, whereas tone is how you respond in a given situation.
Active and passive voice
A sentence always contains an actor, a verb, and a target. The order in which these come determines if the sentence is written in an active or passive voice.
The actor comes first in an active voice. For example: “CSS paints the background.”
Sentences that use an active voice are more straightforward than their counterparts. They’re clearer, shorter, and more understandable — perfect for a more professional voice that gets straight to the point.
With a passive voice, the actor comes last. (See what I did there?) That means our actor — CSS in this case — comes at the end like this: “The background is painted by CSS.”
Readers usually convert a passive voice to an active voice in their heads, resulting in more processing time. If you’ve ever heard that writing in an active voice is better, this is usually the reason why. Tech writers prefer the active voice most of the time, with very few exceptions such as citing research: “It has been suggested that …”
But that doesn’t mean you should always strive for an active voice. Switching from one to the other — even in the same paragraph — can make your content flow more seamlessly from one sentence to another if used effectively.
Avoiding mistakes
Grammar is all about the structure and correctness of language, and there’s nothing better to achieve that than a quick proofreading of your document. It’s very important to rid your writings of spelling mistakes, grammar issues, and semantic imperfections.
At the end of this article, I’ll show you the invaluable tools that professionals use to avoid writing mistakes. Obviously, there are built-in spell checkers in just about everything these days; our code editors even have spell-checking and linting plugins to help prevent mistakes.
But if you’re looking for a one-stop tool for all-things grammar, Grammarly is one of the most widely-used tools. I’m not getting a kickback for that or anything. It’s just a really great tool that many editors and writers use to write clean and clear content — similar to how you might use Emmet, eslint, or any other linter to write clean and clear code.
Writing code comments
The things we write for other developers can have a big impact on the overall quality of our work, whether it’s what we write in the code, how we explain the code, or how we give feedback on a piece of code.
It’s interesting that every programming language comes with a standard set of features to write a comment. They should explain what the code is doing. By that, I don’t mean vague comments like this:
Instead, use comments that provide more information:
It’s all about context. “What kind of program am I building?” is exactly the kind of question you should be asking yourself.
Comments should add value
Before we look at what makes a “good” code comment, here are two examples of lazy comments:
Remember that the purpose of a comment is to add value to a piece of code, not to repeat it. If you can’t do that, you’re better off just leaving the code as-is. What makes these examples “lazy” is that they merely restate what the code is obviously doing. In this case, the comments are redundant because they tell us what we already know — they aren’t adding value!
Comments should reflect the current code
Out-of-date comments are no rare sight in large projects; dare I say in most projects.
Let’s imagine David, a programmer and an all-around cool guy to hang out with. David wants to sort a list of strings alphabetically from A to Z, so he does the obvious in JavaScript:
David then realizes that sortWords() actually sorts lists from Z to A. That’s not a problem, as he can simply reverse the output:
Unfortunately, David didn’t update his code comment.
Now imagine that I didn’t tell you this story, and all you saw was the code above. You’d naturally think that after running that second line of code, `cities` would be sorted from Z to A! This whole confusion fiasco was caused by a stale comment.
While this might be an exaggerated example, something similar can (and often does) happen if you’re racing against a close deadline. Thankfully, this can be prevented by following one simple rule… change your comments the same time you change the code.
That’s one simple rule that will save you and your team from a lot of technical debt.
Now that we know what poorly written comments look like, let’s look at some good examples.
Comments should explain unidiomatic code
Sometimes, the natural way of doing things isn’t right. Programmers might have to “break” the standards a bit, but when they do, it’s advisable to leave a little comment explaining their rationale:
That’s helpful, right? If you were responsible for reviewing this code, you may have been tempted to correct it without that comment there explaining what’s up.
Comments can identify future tasks
Another useful thing to do with comments is to admit that there’s more work to be done.
This way, you can stay focused on your flow. And at a later date, you (or someone else) can come back and fix it.
Comments can link back to the source
So, you just found a solution to your problem on StackOverflow. After copy-pasting that code, it’s sometimes a good thing to keep a link to the answer that helped you out so you can come back to it for future reference.
This is important because solutions can change. It’s always good to know where your code came from in case it ever breaks.
Writing pull requests
Pull requests (PRs) are a fundamental aspect of any project. They sit at the heart of code reviews. And code reviews can quickly become a bottleneck in your team’s performance without good wording.
A good PR description summarizes what change is being made and why it’s being made. Large projects have a pull request template, like this one adapted from a real example:
Avoid vague PR titles
Please avoid titles that look like this:
These don’t even attempt to describe what build, bug, or patch it is we’re dealing with. A little extra detail on what part of the build was fixed, which bug was squashed, or what patch was added can go a long way to establishing better communication and collaboration with your colleagues. It level-sets and gets folks on the same page.
PR titles are traditionally written in imperative tense. They’re a one-line summary of the entire PR, and they should describe what is being done by the PR.
Here are some good examples:
Avoid long PRs
A large PR means a huge description, and no one wants to review hundreds or thousands of lines of code, sometimes just to end-up dismissing the whole thing!
Instead, you could:
Isn’t it much cleaner now?
Provide details in the PR body
Unlike the PR title, the body is the place for all the details, including:
Reporting bugs
Bug reports are one of the most important aspects of any project. And all great projects are built on user feedback. Usually, even after countless tests, it’s the users that find most bugs. Users are also great idealists, and sometimes they have feature ideas; please listen to them!
For technical projects, all of this stuff is done by reporting issues. A well-written issue is easy for another developer to find and respond to.
For example, most big projects come with a template:
Gather screenshots
Capture the issue using your system’s screen-shooting utility.
If it’s a screenshot of a CLI program, make sure that the text is clear. If it’s a UI program, make sure the screenshot captures the right elements and states.
You may need to capture an actual interaction to demonstrate the issue. If that’s the case, try to record GIFs using a screen-recording tool.
How to reproduce the problem
It’s much easier for programmers to solve a bug when it’s live on their computer. That’s why a good commit should come with the steps to precisely reproduce the problem.
Here’s an example:
Suggest a cause
You’re the one who caught the bug, so maybe you can suggest some potential causes for why it’s there. Maybe the bug only happens after you encounter a certain event, or maybe it only happens on mobile.
It also can’t hurt to explore the codebase, and maybe identify what’s causing the problem. Then, your Issue will be closed much quicker and you’re likely to be assigned to the related PR.
Communicating with clients
You may work as a solo freelancer, or perhaps you’re the lead developer on a small team. In either case, let’s say you’re responsible for interfacing with clients on a project.
Now, the programmer stereotype is that we’re poor communicators. We’ve been known to use overly technical jargon, tell others what is and is not possible, and even get defensive when someone questions our approach.
So, how do we mitigate that stereotype? Ask clients what they want, and always listen to their feedback. Here’s how to do that.
Ask the right questions
Start by making sure that you and the client are on the same page:
Asking questions is also a good way to write positively, particularly in situations when you disagree with a client’s feedback or decision. Asking questions forces that person to support their own claims rather than you attacking them by defending your own position:
Questions are a lot more innocent and promote curiosity over animosity.
Sell yourself
If you’re making a pitch to a prospective client, you’re going to need to convince them to hire you. Why should the client choose you? It’s important to specify the following:
And once you get the job and need to write up a contract, remember that there’s no content more intimidating than a bunch of legalese. Even though it’s written for design projects, the Contract Killer can be a nice starting point for writing something much friendlier.
Your attention to detail could be the difference between you and another developer trying to win the same project. In my experience, clients will just as easily hire a develop they think they will enjoy working with than the one who is technically the most competent or experienced for the job.
Writing microcopy
Microcopy is the art of writing user-friendly UI messages, such as errors. I’ll bet there have been times where you as a developer had to write error messages because they were put on the backburner all the way to launch time.
That may be why we sometimes see errors like this:
Errors are the last thing that you want your users to deal with. But they do happen, and there’s nothing we can do about it. Here are some tips to improve your microcopy skills.
Avoid technical jargon
Most people don’t know what a server is, while 100% of programmers do. That’s why it’s not unusual to see uncommon terms written in an error message, like API or “timeout execution.”
Unless you’re dealing with a technical client or user base, It’s likely that most of your users didn’t take a computer science course, and don’t know how the Internet works, and why a particular thing doesn’’t work. Hence, the error.
Therefore, a good error message shouldn’t explain why something went wrong, because such explanations might require using scary technical terms. That’s why it’s very important to avoid using technical jargon.
Never blame the user
Imagine this: I’m trying to log into your platform. So I open my browser, visit your website, and enter my details. Then I’m told: “Your email/password is incorrect.”
Even though it seems dramatic to think that this message is hostile, it subconsciously makes me feel stupid. Microcopy says that it’s never okay to blame the user. Try changing your message to something less finger-pointy, like this this example adapted from Mailchimp’s login: “Sorry, that email-password combination isn’t right. We can help you recover your account.”
I’d also like to add the importance of avoiding ALL CAPS and exclamation points! Sure, they can be used to convey excitement, but in microcopy they create a sense of hostility towards the user.
Don’t overwhelm the user
Using humor in your microcopy is a good idea! It can lighten up the mood, and it’s an easy way to curb the negativity caused by even the worst errors.
But if you don’t use it perfectly, it can come across as condescending and insulting to the user. That’s just a big risk to take.
Mailchimp says it well:
Writing accessible markup
We could easily spend an entire article about accessibility and how it relates to technical writing. Heck, accessibility is often included in content style guides, including those for Microsoft and Mailchimp.
You’re a developer and probably already know so much about accessibility. You may even be one of the more diligent developers that makes accessibility a core part of your workflow. Still, it’s incredible how often accessibility considerations are put on the back burner, no matter how important we all know it is to make accessible online experiences that are inclusive of all abilities.
So, if you find yourself implementing someone else’s copywriting into your code, writing documentation for other developers, or even writing UI copy yourself, be mindful of some fundamental accessibility best practices, as they round out all the other advice for technical writing.
Things like:
<nav>,<header>,<article>, etc.)Andy Bell offers some relatively small things you can do to make content more accessible, and it’s worth your time checking them out. And, just for kicks, John Rhea shows off some neat editing tricks that are possible when we’re working with semantic HTML elements.
Conclusion
Those were six ways that demonstrate how technical writing and development coincide. While the examples and advice may not be rocket science, I hope that you found them useful, whether it’s collaborating with other developers, maintaining your own work, having to write your own copy in a pinch, or even drafting a project proposal, among other things.
The bottom line: sharpening your writing skills and putting a little extra effort into your writing can actually make you a better developer.
Technical writing resources
If you’re interested in technical writing:
If you’re interested in copywriting:
If you’re interested in microcopy:
If you’re interested in using a professional style guide to improve your writing:
If you’re interested in writing for accessibility:
Technical Writing for Developers originally published on CSS-Tricks. You should get the newsletter.
OK, you've added an accessible name to your control. Maybe you've used
aria-label,<label>or some other way to name a control. Now you wonder: what makes a name good, effective or useful?I wrote about why accessible names matter and where to add them before. In this post, I will go into how to make the actual names more user friendly. These tips are all from an underappreciated piece of content that I love: the Composing Effective and User-Friendly Accessible Names section of the ARIA Authoring Practices Guide. All credits go to the authors, I'm just adding context and examples.
Function over form
An accessible name is used by assistive technologies to refer to things on a web page. For instance, if you use voice control, you could say the accessible name of a particular control to activate it. If you use a screenreader, it is the name that gets read out when you get to the control, or when you pull up a list of controls (eg a list of links on the page).
Because of how we use accessible names, we want to keep them functional and avoid naming controls after what they look like. Ideally, you do this in the imperative form, that makes it easiest to quickly grasp what a thing is going to do.
Examples:
Most unique part first
In a series of names, like a set of buttons, links, etc, start with the most unique part of the name. This makes it easier to distinguish them.
Let's say you list a bunch of albums and want to include “album” in each name. Most unique first means you say “Midnight Marauders - Album”, “To Pimp A Butterfly - Album” etc, rather than “Album - Midnight Marauders”, “Album - To Pimp A Butterfly”.
Or you have actions for a link: “Edit link”, “Copy link” and “Share link” work better than “Link edit”, “Link copy” and “Link share”.
This even applies to the
<title>of web pages: if you're repeating your company name in it, leave it for last and list what's unique about the page first. Technically not an accessible name, but the same naming advice happens to apply.Be concise
Keep a name to the most important 1-3 words, prefer brevity.
No roles as part of the name
Things that have names in your page will (or should) have roles too. The browser will derive the role for you, whether you've set it explicitly (e.g.
role="button") or it comes for free with the element (e.g.<button>). If you add the role, for instance the word ‘button’, to the name, that is redundant and this can be annoying for users.Examples:
Keep names unique
Imagine you work in a school and all your students are named “Alice”. It would be hard to address them… this is the same for the names of controls and components in your page, especially for users who use mostly these names to browse the page.
Examples:
Sentences aren't names
The last tip in the document is: start names with a capital letter, for better pronounciation in some screenreaders, and don't end with a period, because a name is not a sentence.
I'm not sure if this is the type that this tip is originally referring to, but one example of setences in accessible names is this: a card that has a title, a description and a picture, that is clickable as a whole, implemented by wrapping it all in one
<a>element. I've seen this in the wild. It is often problematic, because it creates names that are way too long and confusing. My recommendation would be to do this instead: pick a string that is a more useful (and concise) name and make that the<a>. Then solve the clickability issue with CSS.Wrapping up
Before I wrap up, I want to assure you that you don't need to use ARIA to provide names, even if this information is part of the ARIA Authoring Practices. Text content in the appropriate HTML elements (
<label>,<legend>,<caption>,<button>,<a>) works perfectly fine too. An added benefit is that when you provide visible names with these HTML elements, they can be used by more users, including people who don't use assistive technologies and people collaborating with assistive technology users.That's all. As mentioned above, these tips are from Composing Effective and User-Friendly Accessible Names in the W3C's ARIA Authoring Practices. That specific page has a lot more tips and also covers accessible descriptions, name and description calculation, per-role guidance on whether you need a name, lots of gotchas and various coding techniques for adding names. Happy naming!
Thanks to Job for some useful input.@hdv this is all great feedback again. Hey @snugug, you may be interested in this too.
@hdv But nobody gives the money for stuff like that! :) LOL
@hdv I know the feeling! It's shocking for me how many devs obviously only think in terms of a visual, mouse operated user experience 🤦♂️