In the last week of 2020, I decided to export my Goodreads data to display it on my personal website. This post is about what I did and how.
Why export?
First, I quite like Goodreads. It lets me see the reads of friends and acquaintances. It lets me share my own. This is all splendid, but it is still somebody else’s site. Somebody with very different life goals from my own, in fact. For more control on what I display and how, I decided to create a new section of this website dedicated to books, fed by an export of my Goodreads data.
The two main reasons I use Goodreads are people and books. I want to connect with (internet) friends and be inspired by what they read. I also want to keep track of what I have read and plan to read, for instance when a person or article mentions an interesting book. When I’m reading a book review in the paper, I’l sometimes grab my phone and add the thing to the list. Goodreads has an easy to use catalog that usually lists what I searched.
Some things to dislike about the platform are the gamification and the generic recommendations: it’s noise that I could do without (“you read something in philosophy, maybe you’ll like this book by Plato”). There are also lots of trackers, and it is powered by a faceless multi-billion dollar enterprise that threatens the livelihood of friendly, local bookshops.
Some features
Various people’s online bookshelves inspired me to create one on this site, including Melanie Richard’s highlights, focused on highlights, Dave Rupert’s Bookshelf, which features many short reviews and half stars, Tom McWright’s, Maggie Appleton’s, Mandy Brown’s, Alex Chan’s, Sawyer Hollenshead (also with highlights) and Amanda Pinkster (includes where she read them).
I like the processes of other people: Katy Decorah uses GitHub actions, Nienke uses her own What.pm and Jeremy Keith tags notes with ISBN numbers. My process is still different from each of them though, for no particular reason.
For me, a personal book repository does not require a lot, but these are some features I wanted to have:
- Separate views for Dutch and English
- I mostly read in these two languages, some viewers may only be interested in either section.
- Hand-picked book covers
- ‘Never judge a book by its cover’, they say. Well, I like book covers as expectation setters and did not automate the cover art collection process.
- Links to author’s personal sites
- Personal sites deliver on the promise of the web, said Matthias Ott in Make it personal. I haven’t enriched a lot of the data with this piece of information, but will be.
- Dark mode
- Because CSS is fun. I went for a
midnightbluebackground withkhakitext. - No tracking
- This site does not track users. Minimum Viable Data Collection (zero, in this case) ftw.
What I could automate
CSV entries to front matter in Markdown
I decided to use Eleventy to turn my data into a web page, as I like its flexibility, its focus on simplicity and its firm hesitation to make decisions for developers using it.
Goodreads provides reading data in CSV files, which are reasonably well structured. For the Eleventy site, I needed a folder full of Markdown files, one for each book, with basically the metadata from the Goodreads export as Yaml front matter:
---
title: "Uncanny Valley"
author: "Anna Wiener"
isbn: "0374278016"
isbn13: "9780374278014"
rating: "5"
publisher: "MCD"
pages: "281"
publishYear: "2020"
read: "2020"
goodreads_id: "45186565"
---I did this in Node using a slightly modified version of CSV to Markdown. The project is archived and I could not get the Noderize wrapper to work, but the provided script in index.js did the job for me.
It seems like Hay Kranen’s dataknead may be a great alternative to do this work (in Python).
Image processing
This site has a lot of images, and resizing or optimising would not be my definition of fun. I used the official Image plugin for Eleventy to generate correctly sized images from my source images, and the documented Nunjucks shortcode to output a picture element with webp and jpg versions in various sizes.
I used the native lazyloading attribute, loading="lazy" , which I learned only in this project, is not added to the picture-element, but to the fallback <img> .
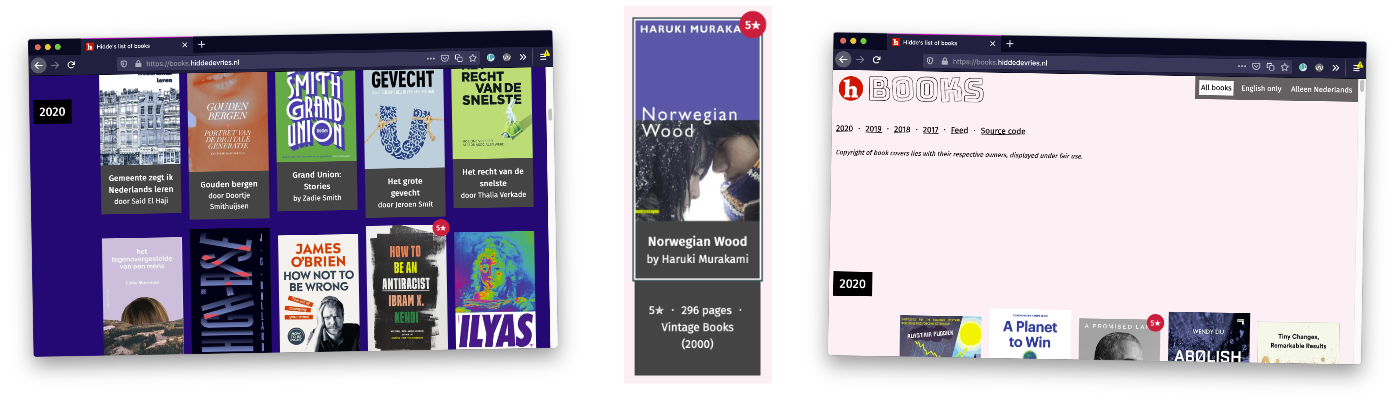
The grid
I knew how I wanted my content to be layed out, but I didn’t know what my content would be. Grid Layout is fantastic if that’s your situation. I used grid’s autoplacement feature: I defined a grid, added the content in HTML and each book magically appeared in its right place.

On small screens, I used the non-default autoflow value column, to make new items appear horizontally.
What I didn’t automate
In web projects, we often balance between spending time to automate versus doing it manually. Sure, automation can be a fun thing to work on. But if I’m honest, I only want to do it if it saves more time than it costs.
Book covers
Cover art is among the highest forms of graphic design. Covers of music and books can be incredibly creative. Film posters can be a prone to cliche overuse, but have you seen Saul Bass’s movie posters?
Books often get different covers when they are reprinted or distributed in different countries. This project was the perfect excuse to handpick my favourite for each book.
CSS authoring
There was not enough complexity to warrant any form of CSS processing, so I just created a single CSS file and started adding styles. I used no methodology or framework. I did mostly avoid classes, because in my day to day work I overuse them and it seemed like a fun challenge.
Extra data
I’ve also added some data manually that I didn’t have in Goodreads, like the language I read a book in. And I want to slowly add more data to some books, like the URI for the author’s personal website, and, in case I wrote a review, a link to that review.
Future features
There are some things that I would like to improve when there’s more time or less lockdown. A website is never finished!
- Some interface to add data
- Adding a new book now involves me manually creating a Markdown file with the right front matter and a JPG file with the same name for the book cover. I could automate at least part of this.
- Filters
- Books can currently display by language. If I started adding tags to books, I could create sub lists, “Show books about topic X”. That would be fairly trivial to do.
- Better sorting
- I messed up transforming the date field in the Goodreads export, so now I only have a year and no way to sort by reading date. I plan to add this for new books.
- RSS
- I doubt anyone would subscribe to something like this, but wide availability of reading list RSS feeds would allow us all to create a decentralised Goodreads in feed reader software of our choice.
- Better lazyloading
- Currently, all images on the book site have the
loading="lazy"attribute. The recommended way is to only add this attribute for images that are not in the viewport. I’m not sure how to solve that on this site, because my grid grows with the viewport. Which images are in your viewport, depends on how wide it is. - Better markup
- Maybe I can use more standard markup for the books, like microformats. The indieweb personal library page has some pointers, including Paul Munday’s example of microformats for books.
Woops, that’s quite the list. Let me just postpone it to the next sprint.
Wrapping up
So, my book site is available on books.hiddedevries.nl, the source is on GitHub. This has been a fun weekend project, and to be honest, I am very much looking forward to continue expanding the existing data and add new stuff.
If you have one of these digital bookshelves yourself, please do share them in the comments or reply on Twitter! If you have any thoughts or opinions on what I’ve done, feel free to let me know.
Comments, likes & shares (1)
In the last week of 2020, I decided to export my Goodreads data to display it on my personal website. This post is about what I did and how.
Why export?
First, I quite like Goodreads. It lets me see the reads of friends and acquaintances. It lets me share my own. This is all splendid, but it is still somebody else’s site. Somebody with very different life goals from my own, in fact. For more control on what I display and how, I decided to create a new section of this website dedicated to books, fed by an export of my Goodreads data.
The two main reasons I use Goodreads are people and books. I want to connect with (internet) friends and be inspired by what they read. I also want to keep track of what I have read and plan to read, for instance when a person or article mentions an interesting book. When I’m reading a book review in the paper, I’l sometimes grab my phone and add the thing to the list. Goodreads has an easy to use catalog that usually lists what I searched.
Some things to dislike about the platform are the gamification and the generic recommendations: it’s noise that I could do without (“you read something in philosophy, maybe you’ll like this book by Plato”). There are also lots of trackers, and it is powered by a faceless multi-billion dollar enterprise that threatens the livelihood of friendly, local bookshops.
Some features
Various people’s online bookshelves inspired me to create one on this site, including Melanie Richard’s highlights, focused on highlights, Dave Rupert’s Bookshelf, which features many short reviews and half stars, Tom McWright’s, Maggie Appleton’s, Mandy Brown’s, Alex Chan’s, Sawyer Hollenshead (also with highlights) and Amanda Pinkster (includes where she read them).
I like the processes of other people: Katy Decorah uses GitHub actions, Nienke uses her own What.pm and Jeremy Keith tags notes with ISBN numbers. My process is still different from each of them though, for no particular reason.
For me, a personal book repository does not require a lot, but these are some features I wanted to have:
Separate views for Dutch and English I mostly read in these two languages, some viewers may only be interested in either section. Hand-picked book covers ‘Never judge a book by its cover’, they say. Well, I like book covers as expectation setters and did not automate the cover art collection process. Links to author’s personal sites Personal sites deliver on the promise of the web, said Matthias Ott in Make it personal. I haven’t enriched a lot of the data with this piece of information, but will be. Dark mode Because CSS is fun. I went for amidnightbluebackground withkhakitext. No tracking This site does not track users. Minimum Viable Data Collection (zero, in this case) ftw.What I could automate
CSV entries to front matter in Markdown
I decided to use Eleventy to turn my data into a web page, as I like its flexibility, its focus on simplicity and its firm hesitation to make decisions for developers using it.
Goodreads provides reading data in CSV files, which are reasonably well structured. For the Eleventy site, I needed a folder full of Markdown files, one for each book, with basically the metadata from the Goodreads export as Yaml front matter:
I did this in Node using a slightly modified version of CSV to Markdown. The project is archived and I could not get the Noderize wrapper to work, but the provided script in
index.jsdid the job for me.It seems like Hay Kranen’s dataknead may be a great alternative to do this work (in Python).
Image processing
This site has a lot of images, and resizing or optimising would not be my definition of fun. I used the official Image plugin for Eleventy to generate correctly sized images from my source images, and the documented Nunjucks shortcode to output a
pictureelement withwebpandjpgversions in various sizes.I used the native lazyloading attribute,
loading="lazy", which I learned only in this project, is not added to thepicture-element, but to the fallback<img>.The grid
I knew how I wanted my content to be layed out, but I didn’t know what my content would be. Grid Layout is fantastic if that’s your situation. I used grid’s autoplacement feature: I defined a grid, added the content in HTML and each book magically appeared in its right place.
On small screens, I used the non-default autoflow value
column, to make new items appear horizontally.What I didn’t automate
In web projects, we often balance between spending time to automate versus doing it manually. Sure, automation can be a fun thing to work on. But if I’m honest, I only want to do it if it saves more time than it costs.
Book covers
Cover art is among the highest forms of graphic design. Covers of music and books can be incredibly creative. Film posters can be a prone to cliche overuse, but have you seen Saul Bass’s movie posters?
Books often get different covers when they are reprinted or distributed in different countries. This project was the perfect excuse to handpick my favourite for each book.
CSS authoring
There was not enough complexity to warrant any form of CSS processing, so I just created a single CSS file and started adding styles. I used no methodology or framework. I did mostly avoid classes, because in my day to day work I overuse them and it seemed like a fun challenge.
Extra data
I’ve also added some data manually that I didn’t have in Goodreads, like the language I read a book in. And I want to slowly add more data to some books, like the URI for the author’s personal website, and, in case I wrote a review, a link to that review.
Future features
There are some things that I would like to improve when there’s more time or less lockdown. A website is never finished!
Some interface to add data Adding a new book now involves me manually creating a Markdown file with the right front matter and a JPG file with the same name for the book cover. I could automate at least part of this. Filters Books can currently display by language. If I started adding tags to books, I could create sub lists, “Show books about topic X”. That would be fairly trivial to do. Better sorting I messed up transforming the date field in the Goodreads export, so now I only have a year and no way to sort by reading date. I plan to add this for new books. RSS I doubt anyone would subscribe to something like this, but wide availability of reading list RSS feeds would allow us all to create a decentralised Goodreads in feed reader software of our choice. Better lazyloading Currently, all images on the book site have theloading="lazy"attribute. The recommended way is to only add this attribute for images that are not in the viewport. I’m not sure how to solve that on this site, because my grid grows with the viewport. Which images are in your viewport, depends on how wide it is. Better markup Maybe I can use more standard markup for the books, like microformats. The indieweb personal library page has some pointers, including Paul Munday’s example of microformats for books.Woops, that’s quite the list. Let me just postpone it to the next sprint.
Wrapping up
So, my book site is available on books.hiddedevries.nl, the source is on GitHub. This has been a fun weekend project, and to be honest, I am very much looking forward to continue expanding the existing data and add new stuff.
If you have one of these digital bookshelves yourself, please do share them in the comments or reply on Twitter! If you have any thoughts or opinions on what I’ve done, feel free to let me know.